Recognizing One Million Celebrities
Training set
More details about the dataset please see the dataset document.
To facilitate the above face recognition task, we provide a large training dataset which covers the top 100K celebrities. This training dataset is prepared by the following steps. First, we select the top 100K entities from the 1M celebrity list in terms of their popularities. Then, we leverage public search engines to provide approximately 100 images for each celebrity, resulting in about 10M web images. Third, we detect, crop, and align faces for all the images for easy usage, while also provide the thumbnails for the original images as reference. Note that the dataset is mainly to facilitate the participants to quickly get started. In the contest, we do not limit the use of external data, but encourage the participants to treat data collection as part of the face recognition challenge.
Download Link
This training set can be downloaded from here (cropped and aligned face images). For reference, the whole images (downsampled due to legal requirement) are provided here, and the cropped face images (without alignment) are provided here.
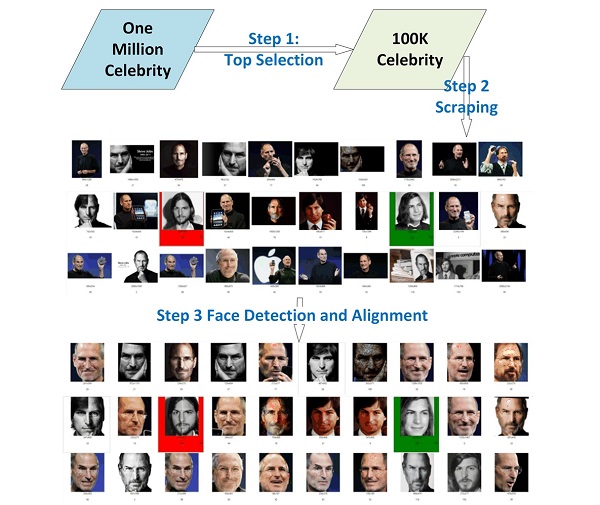
As we have mentioned earlier, we do NOT manually remove the noise in this training data set. This is partially because to prepare training data of this size is beyond the scale of manual labeling. In addition, we have observed that the state-of-the-art deep neural network learning algorithm can tolerate a certain level of noise in the training data. Though for a small percentage of celebrities their image search result is far from perfect, more data especially more individuals covered by the training data could still be of great value to the face recognition research. Moreover, we believe that data cleaning, noisy label removal, and learning with noisy data are all good and real problems that are worth of dedicated research efforts. Therefore, we leave this problem open and even do not limit the use of outside training data.
Besides, the current provided training set in MS-Celeb-1M.v1 only covers about 75% of celebrities in our measurement set, which implies that the upper bound of recognition recall rate based on the provided training data cannot exceed 75%. This is mainly due to two considerations. First, being limited by time and resource, we can only manage to prepare a dataset of top 100K celebrities as a v1 dataset to facilitate the participants to quickly get started. We will continuously extend the dataset to cover all the 1M celebrities in the future. Second, we encourage the participants to treat the dataset development as one of the key problems in this challenge, and explicitly point out that external datasets are not prohibited.
Measurement set
In order to concretely measure the performance on our challenge, we build the measurement set using the following steps.
First, we select 1500 celebrities from our one-million celebrity list. The celebrities are selected in a way that, our measurement set mainly focuses on popular celebrities to represent the interest of real application and users, while the measurement set still maintains enough (about 25%) tail celebrities to encourage the performance on celebrity coverage. We hope the uncovered 25% of celebrities in the measurement can encourage people label their data with entity keys in the freebase snapshot we provided and publish, so that different dataset could be easily merged to facilitate collaboration.
Then, we scrape images for these selected celebrities using multiple search queries to introduce image variance. Afterwards, we manually label the scraped images for these celebrities carefully. The correctness of our labeling is ensured by deep research on the web content, consensus verification, and multiple iterations of carefully review. In order to make our measurement more challenging, we blend a set of distractor images with this set of carefully labeled images. The distractor images are images of other celebrities or ordinary people on the web, which are mainly used to hide the celebrities we select in the measurement.
Third, We select two images per celebrity from all the labeled images and form the following two sets.
-
Random set: The image in this subset is randomly selected from the labeled images. One image per celebrity. This set reveals how many celebrities are truly covered by the models to be tested.
-
Hard set: The image in this subset is the one (from the labeled images) which is the most different from any images in the training dataset. One image per celebrity. This set is to evaluate the generalization ability of the model, and the robustness of the model on complex situations caused by pose/age/resolution/special effects/etc..
Afterall, we publish the random set and hard set for 500 celebrities for development and debugging purpose, and hold the random set and hard set for the rest 1000 celebrities as the official measurement set.
Download Link
The development set is published here.
